fitter module reference¶
Main module of the fitter package.
This module provides the Fitter class for fitting multiple probability distributions to data samples and comparing their goodness of fit using various metrics.
- class fitter.fitter.Fitter(data: ndarray | list[float], xmin: float | None = None, xmax: float | None = None, bins: int = 100, distributions: list[str] | str | None = None, timeout: int = 30, density: bool = True, verbose: bool = True)[source]¶
Fit a data sample to known distributions
A naive approach often performed to figure out the undelying distribution that could have generated a data set, is to compare the histogram of the data with a PDF (probability distribution function) of a known distribution (e.g., normal).
Yet, the parameters of the distribution are not known and there are lots of distributions. Therefore, an automatic way to fit many distributions to the data would be useful, which is what is implemented here.
Given a data sample, we use the fit method of SciPy to extract the parameters of that distribution that best fit the data. We repeat this for all available distributions. Finally, we provide a summary so that one can see the quality of the fit for those distributions
Here is an example where we generate a sample from a gamma distribution.
>>> # First, we create a data sample following a Gamma distribution >>> from scipy import stats >>> data = stats.gamma.rvs(2, loc=1.5, scale=2, size=20000) >>> # We then create the Fitter object >>> import fitter >>> f = fitter.Fitter(data) >>> # just a trick to use only 10 distributions instead of 80 to speed up the fitting >>> f.distributions = f.distributions[0:10] + ['gamma'] >>> # fit and plot >>> f.fit() >>> f.summary() sumsquare_error aic bic kl_div ks_statistic ks_pvalue loggamma 0.001176 995.866732 -159536.164644 inf 0.008459 0.469031 gennorm 0.001181 993.145832 -159489.437372 inf 0.006833 0.736164 norm 0.001189 992.975187 -159427.247523 inf 0.007138 0.685416 truncnorm 0.001189 996.975182 -159408.826771 inf 0.007138 0.685416 crystalball 0.001189 996.975078 -159408.821960 inf 0.007138 0.685434
Once the data has been fitted, the
summary()method returns a sorted dataframe where the index represents the distribution names.The AIC is computed using
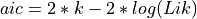 ,
and the BIC is computed as
,
and the BIC is computed as  .
.where Lik is the maximized value of the likelihood function of the model, n the number of data point and k the number of parameter.
Looping over the 80 distributions in SciPy could takes some times so you can overwrite the
distributionswith a subset if you want. In order to reload all distributions, callload_all_distributions().Some distributions do not converge when fitting. There is a timeout of 30 seconds after which the fitting procedure is cancelled. You can change this
timeoutattribute if needed.If the histogram of the data has outlier of very long tails, you may want to increase the
binsbinning or to ignore data below or above a certain range. This can be achieved by setting thexminandxmaxattributes. If you set xmin, you can come back to the original data by setting xmin to None (same for xmax) or just recreate an instance.- distributions: list[str]¶
list of distributions to test
- fit(progress: bool = False, n_jobs: int = -1, max_workers: int = -1, prefer: str = 'processes') None[source]¶
Fit all distributions to the data and compute goodness-of-fit metrics.
Loops over all distributions in parallel and finds the best parameters to fit the data. Populates the following attributes:
df_errors: DataFrame with sum of squared errors and information criteriafitted_param: Parameters that best fit the data for each distributionfitted_pdf: PDF values generated with the fitted parameters
- Args:
progress: If True, display progress bar during fitting. n_jobs: Number of jobs for parallel processing (deprecated, use max_workers). max_workers: Number of parallel workers (-1 for all CPUs). prefer: Joblib parallelization method (‘processes’ or ‘threads’).
- Note:
The fitting uses parallel processing for speed. Distributions that fail or timeout are assigned infinite error values.
- get_best(method: str = 'sumsquare_error') dict[str, dict[str, float]][source]¶
Return the best fitted distribution and its parameters.
- Args:
method: Metric to use for ranking (‘sumsquare_error’, ‘aic’, ‘bic’, etc.).
- Returns:
Dictionary with distribution name as key and parameter dictionary as value. Example: {‘gamma’: {‘a’: 2.0, ‘loc’: 1.5, ‘scale’: 2.0}}
- hist() None[source]¶
Draw normalized histogram of the data using
bins.- Examples:
>>> from scipy import stats >>> data = stats.gamma.rvs(2, loc=1.5, scale=2, size=20000) >>> import fitter >>> fitter.Fitter(data).hist()
- plot_pdf(names: list[str] | str | None = None, Nbest: int = 5, lw: float = 2, method: str = 'sumsquare_error') None[source]¶
Plot probability density functions of fitted distributions.
- Args:
- names: Distribution name(s) to plot. If None, plots the Nbest distributions.
Can be a single string or list of strings.
Nbest: Number of best-fitting distributions to plot (when names is None). lw: Line width for the plots. method: Metric to use for ranking distributions (‘sumsquare_error’, ‘aic’, ‘bic’, etc.).
- summary(Nbest: int = 5, lw: float = 2, plot: bool = True, method: str = 'sumsquare_error', clf: bool = True) DataFrame[source]¶
Display summary of best fitting distributions.
- Args:
Nbest: Number of best distributions to include in summary. lw: Line width for plots. plot: If True, create histogram and PDF overlay plot. method: Metric to use for ranking distributions. clf: If True, clear figure before plotting.
- Returns:
DataFrame with fitting results for the Nbest distributions.
- property xmax: float¶
consider only data below xmax. reset if None
- property xmin: float¶
consider only data above xmin. reset if None
histfit module reference¶
Histogram fitting module for Gaussian distributions.
This module provides functionality to fit Gaussian distributions to histogram data, with support for error estimation through Monte Carlo sampling.
- class fitter.histfit.HistFit(data: list[float] | ndarray | None = None, X: ndarray | None = None, Y: ndarray | None = None, bins: int | None = None)[source]¶
Fit and plot Gaussian distributions to histogram data.
This class fits a Gaussian (normal) distribution to histogram data using least squares optimization with optional Monte Carlo error estimation.
The input can be either: - Raw data: Histogram is computed automatically - Pre-computed histogram: X (bin centers) and Y (densities) arrays
For better parameter estimation, the fit can be repeated with added noise (controlled by error_rate) to estimate uncertainty in mu, sigma, and amplitude.
- Examples:
>>> from fitter import HistFit >>> import scipy.stats >>> data = [scipy.stats.norm.rvs(2, 3.4) for _ in range(10000)] >>> hf = HistFit(data, bins=30) >>> hf.fit(error_rate=0.03, Nfit=20) >>> print(hf.mu, hf.sigma, hf.amplitude)
Using pre-computed histogram: >>> Y, X, _ = plt.hist(data, bins=30, density=True) >>> hf = HistFit(X=X, Y=Y) >>> hf.fit(error_rate=0.03, Nfit=20)
- Attributes:
mu (float): Mean of the fitted Gaussian distribution. sigma (float): Standard deviation of the fitted distribution. amplitude (float): Amplitude scaling factor. X (np.ndarray): Bin centers of the histogram. Y (np.ndarray): Probability density values.
- Warning:
Currently handles only Gaussian distributions. API may change in future versions.
- fit(error_rate: float = 0.05, semilogy: bool = False, Nfit: int = 100, error_kwargs: dict[str, Any] | None = None, fit_kwargs: dict[str, Any] | None = None) tuple[float, float, float][source]¶
Fit Gaussian distribution to histogram data with error estimation.
Performs multiple fits with added noise to estimate parameter uncertainty. Creates two figures: one showing individual fits, another showing uncertainty bands.
- Args:
error_rate: Relative error to add as Gaussian noise (e.g., 0.05 = 5%). semilogy: If True, use logarithmic y-axis for the plot. Nfit: Number of Monte Carlo iterations for error estimation. error_kwargs: Plotting kwargs for individual noisy fits (default: thin black transparent lines). fit_kwargs: Plotting kwargs for final averaged fit (default: thick red line).
- Returns:
Tuple of (mu, sigma, amplitude) from the averaged fit.